Den 24. og 25. oktober 2012 afholdte IVA den tiende udgave af AMR, den internationale workshop om adaptive mutimedia retrieval.
Workshoppen var arrangeret af Andreas
Nürnberger og Sebastian Stober
fra Otto-von-Guericke-University i Magdeburg, Marcin
Detyniecki fra Centre National de la Researche Scientifique ved
LIP6 i Paris samt
Birger Larsen, lektor ved IVA.
Hvad er adaptive multimedia retrieval?
I takt med at internettet i eksponentiel grad fyldes af
information i form af video, lyd og billeder, bliver det i stadig
højere grad klart, at der behøves nye måder at søge i, kategorisere
og præsentere al denne information. På AMR 2012 workshoppen
fremlægges forskning i og erfaringer med intelligente måder at
imødekomme behovet for information retrieval i multimedier.
Ifølge Adreas Nürnberger, som er program chair for workshoppen, er
idéen bag AMR "to exchange ideas between communities. We started it
10 years ago, as there were usually problems of adaptivity in
information retrieval interfaces not covered by the main
conferences."
Problematikken indenfor feltet bliver i høj grad et spørgsmål om
at få computeren til at se verden sådan, som vi som mennesker gør
og vice versa. Professor Lars Kai Andersen fra DTU, en af tre
keynote speakers ved workshoppen, præsenterede billedet nedenfor.
De fleste vil uden problemer kunne genkende omridset af en
dalmatiner i det plettede mønster til venstre, hvorimod opgaven for
en computer er næsten umulig.
 En
gestalt-tegning af en dalmatiner
En
gestalt-tegning af en dalmatiner
Dermed bliver opgaven med multimedia information retrieval et
spørgsmål om at mægle mellem mennesker og computere og omsætte
vores komplekse kognitive komponenter til elementer, som computeren
forstår og ligeledes den anden vej med de data, som returneres.
Dermed søges der at bygge bro over den semantiske kløft mellem
menneske og maskine, som Mark Hughes fra Dublin City University
udtrykte det i sin præsentation.
AMR 2012
På AMR udforskes forskellige tilgange til problemstillingen.
Keynote speaker Lars Kai Hansen prøver i sin forelæsning "The
Cognitive Components of Digital Media" at bryde medier ned i mindre
bestanddele set ud fra menneskets kognitive mønstre. Anca-Livia
Radu m.fl. fra University of Trento forsøger at bruge crowd-sourced
(altså, brugergenereret) analyse af billeder til at bestemme
ensartethed og forskellighed. Andre bruger lokation som en
parameter til at inddele og kategorisere video, audio og billeder.
David Hauger og Markus Schedl fra Johannes Keplet University, Linz
bruger for eksempel en brugers placering igennem Twitter,
sammenholdt med de tweets om musik som brugeren poster, til at
samle information om musikpræferencer i et geografisk
perspektiv.
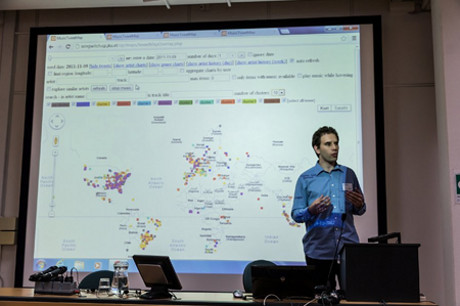
David Hauger og Markus Schedl har udviklet et program til at
undersøge mønstre i musikpræferencer ud fra data indsamlet fra
Twitter. Foto: Sebastian Stober.
Når brugeren selv kigger under hjelmen
Gæsteforedragsholder Professor Arjen P. De Vries fra CWI Amsterdam
benytter en anden tilgang til informationssøgning, end den vi ser
mest i dag. De Vries arbejder i øjeblikket på et søgningsværktøj
ved sit firma Spinque, der i højere grad er gennemsigtigt og
tillader brugeren at beholde muligheden for at redigere
søgekriterierne, i stedet for at værktøjet tilpasser sig brugeren.
I stedet for at lade computeren antage søgekriterierne og afveje
dem internt inden resultatet forevises brugeren, ser De Vries på
hvilke muligheder, der opstår, hvis brugeren i højere grad kan se
'under hjelmen' på maskineriet og selv modificere indstillingerne.
Dette minder om en tidligere måde at søge på, hvor brugeren gerne
skulle kende til wildcards og boolean operators (som f.eks. at hvis
man skriver "horse AND carriage" returneres kun de resultater hvor
begge ord opstår), inden algoritmerne bag søgemaskiner blev så
intelligente, at det ikke længere var nødvendigt.

Arjen P. De Vries præsenterer sin tilgang til information
retrieval med mere integreret brugerkontrol og transparens. Foto:
Sebastian Stober.
De Vries mener, at mere gennemsigtighed giver brugeren en måde at
tage over på, når systemet fejler, men også at der er risiko for,
at for mange håndtag at stille på
potentielt kan gøre søgeresultatet dårligere og mere
uoverskueligt. På denne måde med øget gennemsigtighed giver det
også brugeren en mulighed for at undgå 'filter bubbles'. Filter
bubbles opstår, når f.eks. google antager visse ting om brugerens
interesser og prioriterer søgeresultater baseret på disse
antagelser. Dette bevirker, at søgeresultaterne i højere grad ikke
afspejler virkeligheden, som den forekommer men med en vis
forudindtagethed i forhold til brugeren. Se en
TED Talk om filter bubbles.
Af Stíne Rosenbeck
Christensen